


(文/陈济深剪辑/张广凯)
在狂飙突进的AI时期,算力芯片的"卡脖子"是显性的。
昔时几年里,全行业都在盯着GPU的穷乏,国内企业也纷繁在这个赛谈上发力。如今,跟着国产规划芯片的短板被徐徐填补,算力底座的初步成型也曾有目共睹。
关联词,当悉数东谈主认为跨过GPU这谈坎就能运动无阻时,另一个荫藏却致命的空缺显现了出来。
跟着大模子参数从千亿迈向万亿,算力集群的畛域正从千卡走向万卡,并加快向十万卡靠近。据工信部本年1月表现的数据,我国已建成万卡智算集群42个,智能算力畛域跨越1590EFLOPS。而在这个量级下,决定系统存一火的不只纯是单张显卡有多强,而是千千万万张卡能弗成连在全部高效职责——而将它们连在全部的中枢时期,高速互联收集,正值依然被英伟达紧紧掌控着。
在GPU赛谈演出过一次的脚本,正在互联收集这条赛谈上酝酿重演。
3月12日,中科晨曦阐扬发布首款全栈自研的400G原生无损RDMA高速收集——scaleFabric,从底层的112GSerDesIP、硬件斥地到表层惩办软件齐备100%自研。中国工程院院士邬贺铨评价称,scaleFabric"补皆了国产高速收集的短板"。这款产物的问世,填补这个浮出水面的要道空缺。

十万卡集群的"存一火线"
停止大畛域智算集群的运作逻辑,就能看清这根"传送带"为怎样此致命。
锻练一个万亿参数的大模子,单张GPU的算力远远不够,必须将雨后春笋的加快卡构成集群协同规划。在散播式锻练中,每一轮迭代放弃后,悉数节点都需要同步各自规划出的梯度参数——这个历程叫作念AllReduce。它要求集群中每一个节点险些在合并时刻完成数据交换,任何一个节点的通讯延长,都会拖慢通盘集群的锻练进程。
当集群畛域从千卡扩展到万卡,参与同步的节点数目增长了十倍,但节点间的通讯旅途和潜在冲突是指数级增长的。照顾标明,在大畛域散播式锻练中,收集通讯耗时占比已达到30-50%。这意味吐花重金购入的规划卡,有快要一半时候不是在规划,而是在等数据搬运完成。
中科晨曦高档副总裁李斌在产物发布会上直言:"规划决定了规划系统性能的上限,然而如果是收集系统拉垮的话,有可能会把通盘性能下限归零了。"他在会后对不雅察者网进一步证明,十万个节点要协同好,"能褂讪跑上一个小时、两个小时,这个时期挑战终点大"。
北京科技大学规划机与通讯工程学院储根深从用户角度印证了这一判断:在以往的大畛域规划中,"大部分的时候是在通讯方面",算力行使率经常只消百分之六七十。"在硬件上把通讯的性能补皆之后",行使率不错进步到80%至90%。在算力终点上流的今天,每提高十个百分点的行使率,都是真金白银。
这个需求的畛域正在急剧推广。
昔时以CPU为中枢的规划节点,一台行状器只需要一张网卡;如今以GPU为中枢,一台机器要出八张以致更多。李斌算了一笔账:"比拟底本的数据中心高速收集的用量,基本上提高了10到20倍。"收集也曾从算力基础设施的副角,酿成了增量最大的主角。
悬在国产算力头顶的断供风险
制造这根顶级"传送带"的中枢时期,恒久以来并不在中国企业手里。
当今,数据中心高速收集畛域存在两条主流时期道路。一条是RoCE(RDMAoverConvergedEthernet),本色上是在传统以太网基础上嫁接RDMA辛苦平直内存打听本事。这条道路的上风在于兼容现存以太网基础设施,部署门槛较低,国内也有不少厂商在作念。但它的问题相通显著:以太网自身并非为高性能规划联想,在超大畛域集群场景下,拥塞遏抑、无损传输和扩展性都存在自然短板。
另一条是InfiniBand(IB)原生道路,这是一套从底层公约栈运转就专为高性能规划和低延长通讯量身定制的时期体系。在带宽、时延、无损传输等要道商酌上,IB都是公认的顶级水准。
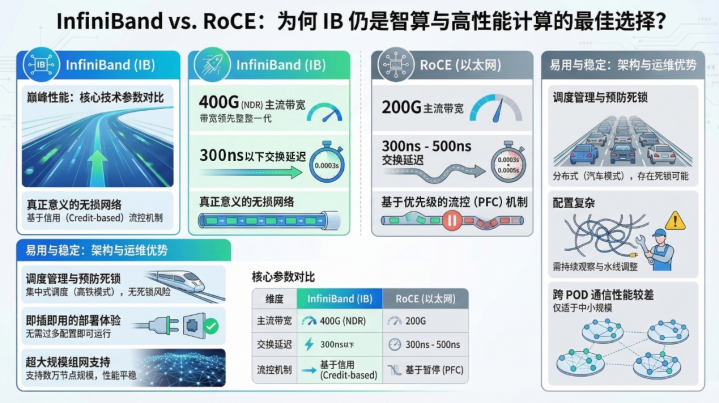
把柄TOP500榜单,当今全球约60%的高性能规划系统接纳InfiniBand收集架构。在全球最大畛域的AI锻练集群中,IB更是近乎标配。
但IB道路靠近一个严峻的产业执行:尽管IB公约自身是灵通圭表,但中枢交换芯片、商用斥地、生态适配险些被英伟达独家掌控。
BG真人(BigGaming)官方网站更要道的是,这不仅是时期壁垒,还在演变为贸易绑缚。英伟达收购IB之后,在鼓舞历程中绑定越来越精雅,除了时期上,还有贸易花样上的绑定。
关于正在崛起的国产AI算力而言,这是一个极其危急的信号。当你倾尽全力造出了国产大模子和国产算力卡,准备搭建万卡以致十万卡集群时,却发现惟一得志需求的互联收集只存在于别东谈主的封闭生态里。如果说规划芯片的断供是"明面上的闭塞",那么高速互联收集的阁下,便是随时可能勒紧的"暗门"。
规划“卡脖子”以外,BG真人(BigGaming)官网可能立地便是收集,其齐备在也曾感受到了。
被逼出来的全栈自研
面对这堵墙,中科晨曦的研发团队领先也试图找到一条更快的路。
技俩启动之初,团队系统评估了险些悉数可行的时期捷径:平直购买熟习的IB链路IP作念集成、在开源决议基础上二次开发、概况退而求其次走RoCE道路。
但评估着力令东谈主懊丧——市面上可取得的IP够不上支握超大畛域集群的性能和可靠性要求;开源决议的性能天花板太低;而RoCE道路诚然上手快,但从根蒂架构上无法提供原生IB的无损传输和极致时延。
中科晨曦高速收集互联产物部总工程师万伟坦言了其时的窘境:"一运转咱们贪图买一些IB的(链路IP),然而发现如实都不适合咱们的要求,咱们终末只消招团队相当作念这个事情。"
悉数捷径都走欠亨,只剩下一条最难的路:从底层物理层运转,全栈自研一套原生IB体系。
这意味着要从零搭建一个齐全的时期垂直栈——最底层是112GSerDes高速串行接口IP,这是决定信号传输质料的物理基础,与芯片制造工艺强关连,是通盘链条中最硬的"硬骨头";往上是自研的交换芯片,负责海量数据包的高速转发和路由休养;再往上是基于这些芯片打造的网卡和交换机硬件;最顶层则是驱动次序、收集惩办软件以及与表层通讯库的适配。从晶体管级到应用层,每一层都必须我方啃下来。
李斌回忆这段历程时莫得侧目不祥情趣:"这个历程咱们作念的终点糟糕,最运转作念的时候,也莫得那么多信心说这个出来能达到IB的水平。"
但着力超出预期,恰正是因为团队此前恒久使用外洋IB产物,对其联想中的不及了如指掌。李斌说:"我毕竟是站在巨东谈主肩膀上,底本咱们用他的产物也终点多,他中间不太好的联想,咱们自研的历程中不错更动,不错去规避。"
最终交出的scaleFabric400系列产物,中枢时期商酌为:端到端通讯时延低至0.9微秒,链路故障规复时候小于1毫秒,单据网互连畛域达到传统InfiniBand的2.33倍,表面可支握最大11.4万卡集群部署。
万伟对不雅察者网暗示,"这是网卡性能的上限”。这跟英伟达CX7在合并个水平线上,交换机单端口带宽800Gbps,整机交换容量达双向64Tbps,交换时延约260纳秒。与英伟达NDR比拟,交换机端口密度进步25%,网卡最大QP数支握进步100%,同期收集总老本镌汰约30%。
储根深算作沉寂的高校用户,给出了我方的评价:"其实这两个差未几合并眉目,以致咱们比他高。"他额外补充了一个前提——晨曦当今主若是在国产硬件和算力上完成的考据,"英伟达最新的GPU,咱们很难买到"。换句话说,这个得益是在受限条目下取得的。
这些也不仅仅纸面参数。这套国产收集已在国度超算互联网位于郑州的中枢节点褂讪运行超10个月,支握起3万卡畛域的智算集群,承载果真大模子锻练任务。该收集系统仅用36小时便完成三套万卡级集群的收集部署上线。国产原生RDMA收集,也曾从"能弗成作念"跨入了"能弗成用好"的阶段。
这标记着中国在智算基础设施的要道一环——高速收集畛域,已从"跟跑"走向"并跑"。
用灵通生态给出"国产谜底"
冲破旧的阁下,毫不虞味着要建立一个新的封闭帝国。
外洋巨头的强硬,很大程度上来自从芯片到收集到软件的闭环生态锁定。但中国算力产业的面目不同——现时国内多款AI芯片百花皆放,如果高速收集也走绑定道路,只会制造新的内讧。李斌的格调很明确:"别一家独大,把通盘时期作念灵通,市集的蛋糕内行分享。"
不外,李斌对InfiniBand的定性并非简便的"封闭"二字。"从某种预见上说,英伟达体系内构建了自身闭环生态。"但他同期指出,"它有我方的公约、圭表组织,某种预见上亦然灵通的。"中科晨曦的政策,是在秉承InfiniBand灵通性的基础上,冲破其在英伟达体系内的贸易绑定。
因此,scaleFabric从第一天起就教学了灵通逻辑:提供圭表化收集接口,不作念自家业务的强制绑定,向下兼容国内不同厂商的算力芯片。在时期道路上也预留了会通空间——畴昔将在原生RDMA基础上探索对RoCE的兼容,让不同道路的用户都能接入。
与此同期,中科晨曦牵头在光合组织下设立了AIDC高速收集职责组。

晨曦信息产业(北京)有限公司副总裁李柳证明了职责组要作念的中枢事情:建立颐养时期圭表——"畴昔的圭表不建立起来,如故让内行走许多无效的旅途";基于灵通平台作念生态适配,让更多用户使用和响应;连合国内科研力量,推动产学研用协同。
这种灵通政策的底层逻辑很了了:要剖析一个封闭生态,靠一家公司远远不够,必须让通盘国产产业链都能参与进来。
从显性的规划芯片bg真人app官网下载,到隐性的互联收集,中国算力产业正在一步步夺回底层基础设施的自主权。当万卡乃至十万卡集群成为大模子锻练的常态确立时,咱们终于不错阐述:在这座雄伟的超等数字工场里,不仅有了国产的"腹黑",也果真收受了至关进军的"动脉"。
 备案号:
备案号: